|
I am an AI researcher. I defended my PhD from the International Max Planck Research School for Intelligent Systems, after working in the lab of Matthias Bethge under the supervision of Wieland Brendel. I've completed my Bachelors and Masters from the Cooper Union, and have spent time at Entrepreneurs First, Flagship Pioneering, Google Brain, Meta AI, Amazon, Borealis AI and IBM Research. My research has focused on adversarial robustness, representation learning, and compositional generalization.
|

|
|
|
|
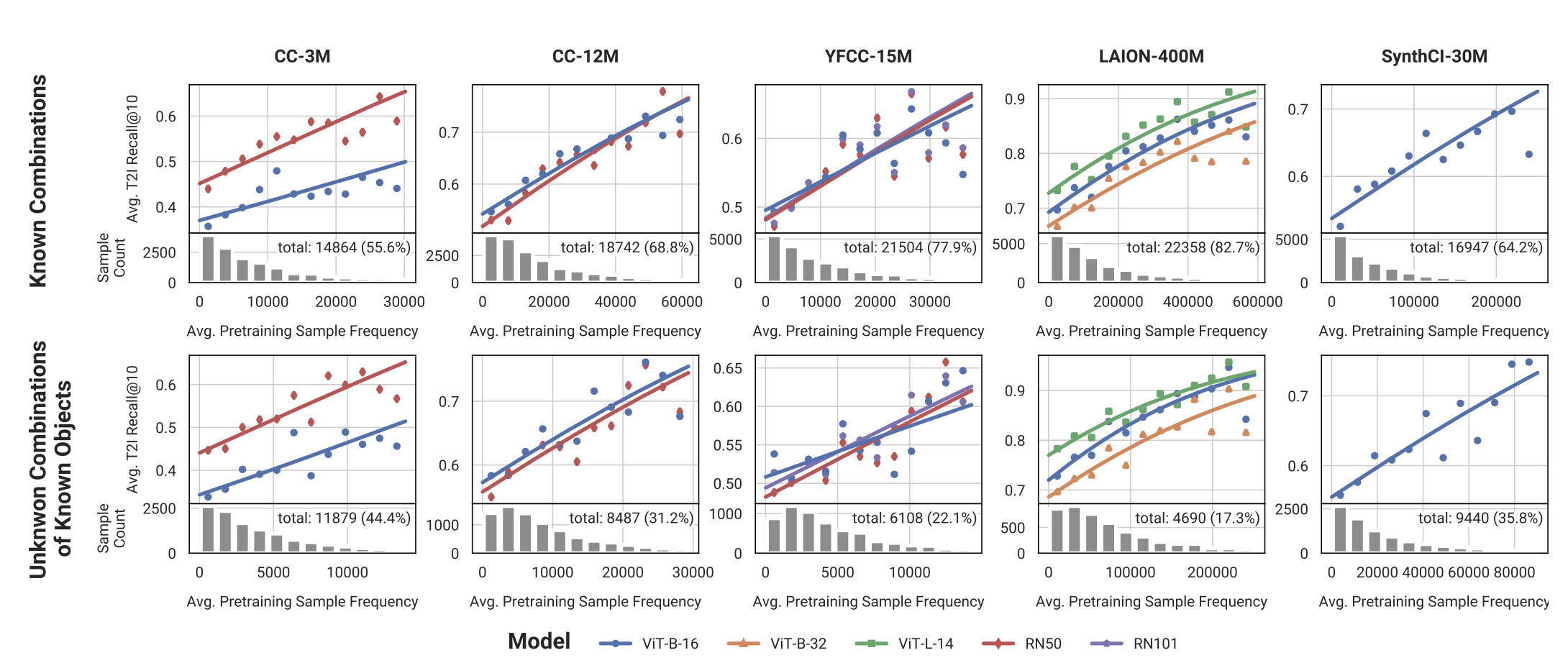
Thaddäus Wiedemer*, Yash Sharma*, Ameya Prabhu, Matthias Bethge, Wieland Brendel (*equal contribution) NeurIPS Compositional Learning Workshop, 2024 paper Compositional generalization of CLIP models on real-world retrieval tasks can consistently be predicted from pretraining frequencies. |
|
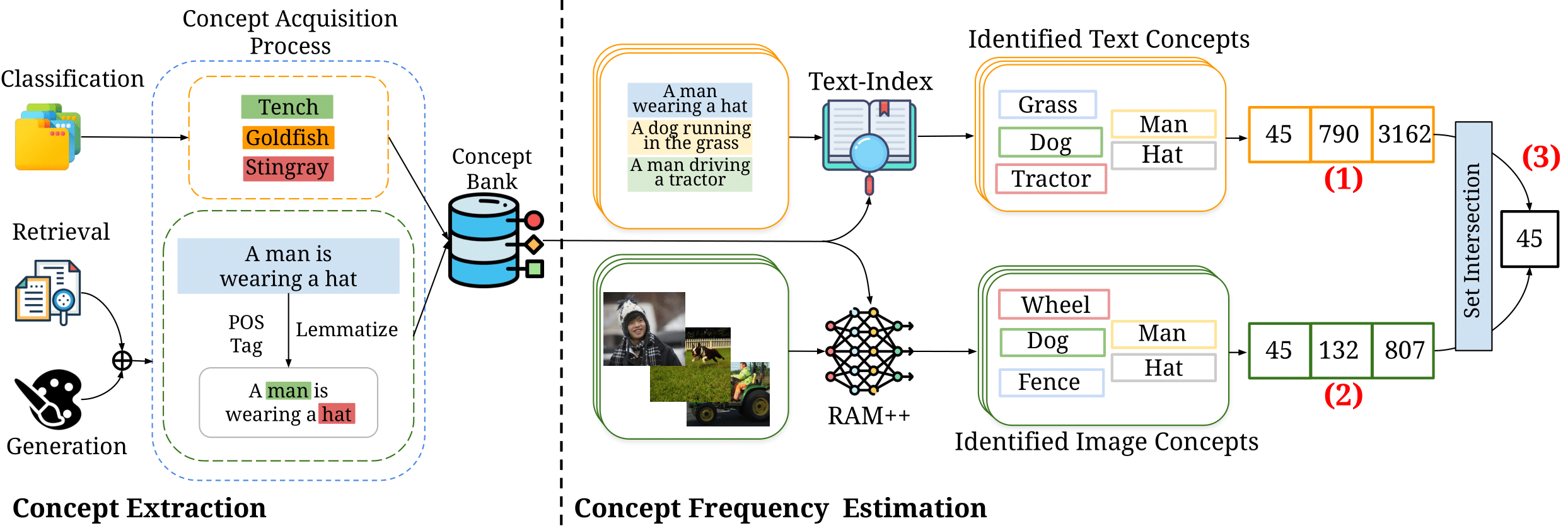
Vishaal Udandarao*, Ameya Prabhu*, Adhiraj Ghosh, Yash Sharma, Philip H.S. Torr, Adel Bibi, Samuel Albanie, Matthias Bethge (*equal contribution) NeurIPS, 2024 paper / code / benchmark Increasing training data frequency of concepts exponentially yields linear improvements in downstream "zero-shot" performance, thus constituting sample inefficient log-linear scaling. |
|
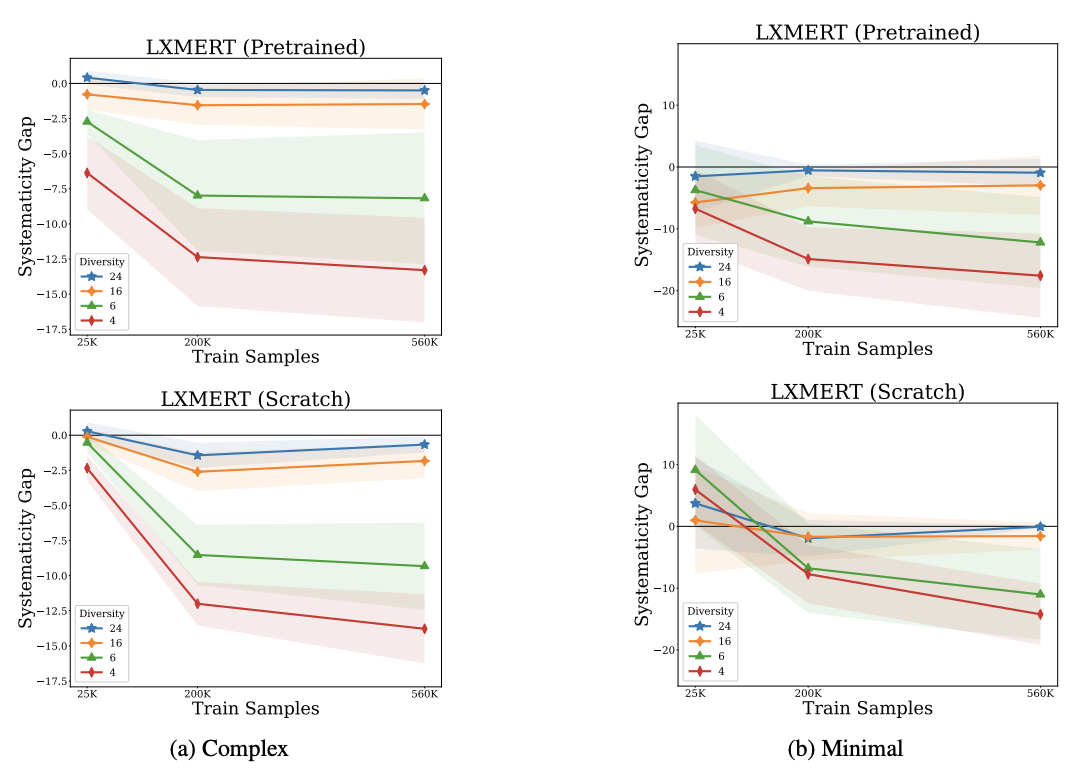
Ian Berlot-Attwell, A. Michael Carrell, Kumar Krishna Agrawal, Yash Sharma†, Naomi Saphra† (†senior author) EMNLP, 2024 paper Increasing training data diversity of attributes in unseen combinations reduces the systematicity gap in visual question answering. |
|
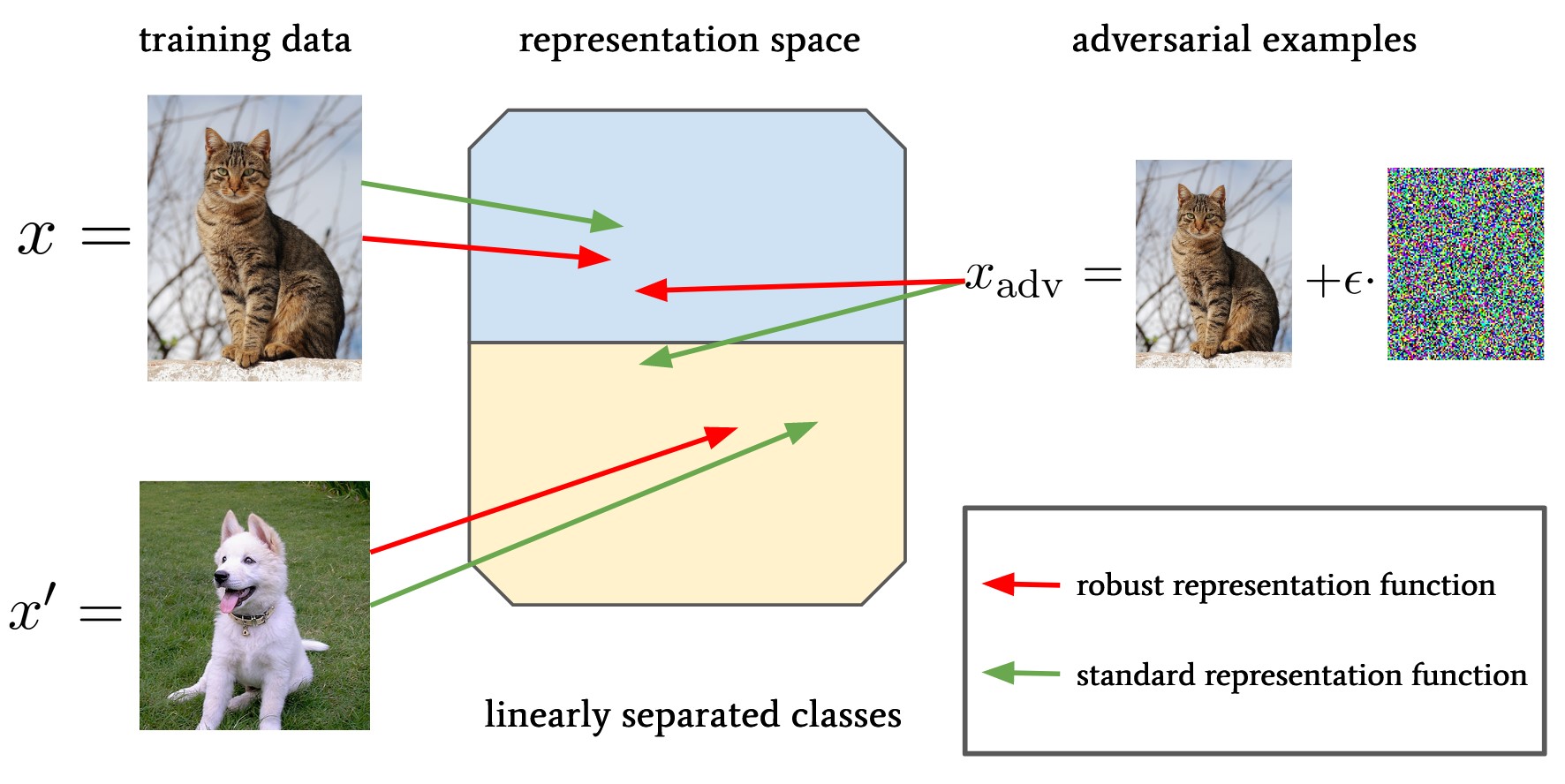
Laura Fee Nern, Harsh Raj, Maurice Georgi, Yash Sharma† (†senior author) NeurIPS, 2023 KDD AdvML Workshop, 2022 paper / code Bounding the robustness of a predictor on downstream tasks by the robustness of the representation that underlies it. |
|
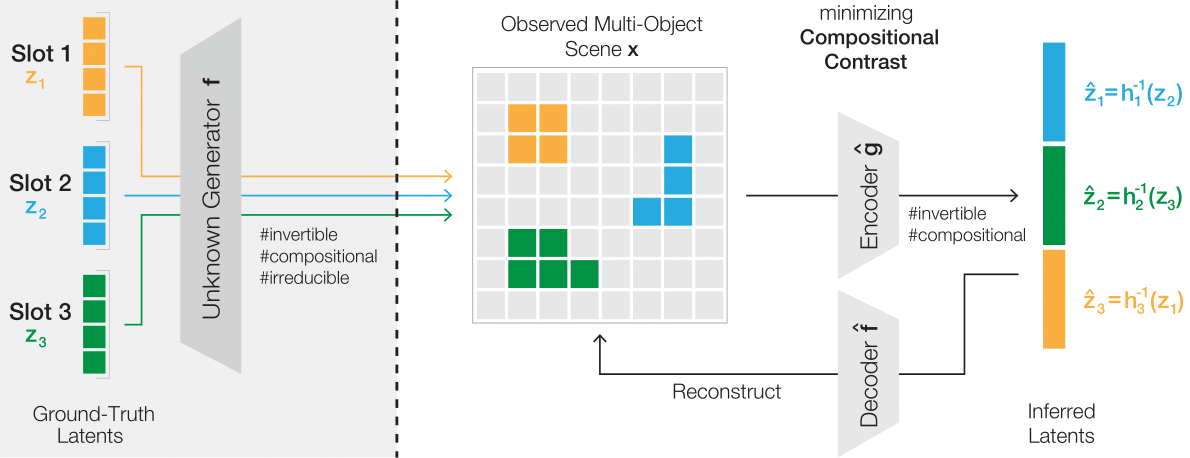
Jack Brady*, Roland S. Zimmermann*, Yash Sharma, Bernhard Schölkopf, Julius von Kügelgen, Wieland Brendel (*equal contribution) ICML, 2023 paper / code Identifying ground-truth object representations, even in the presence of dependencies between objects, by learning an invertible and compositional inference model. |
|
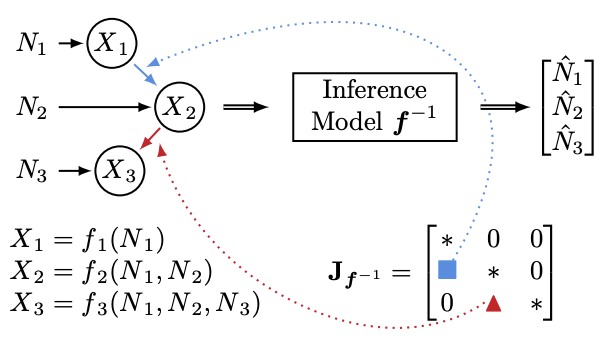
Patrik Reizinger, Yash Sharma, Matthias Bethge, Bernhard Schölkopf, Ferenc Huszár, Wieland Brendel TMLR, 2023 UAI CRL Workshop, 2022 paper / code Uncovering causal relationships from observational data by relying on the Jacobian of the function inferring the underlying sources from the observed variables. |

|
Yash Sharma, Yi Zhu, Chris Russell, Thomas Brox ICML Pre-training Workshop, 2022 paper Match local features at different points in time by tracking points with optical flow. |
|
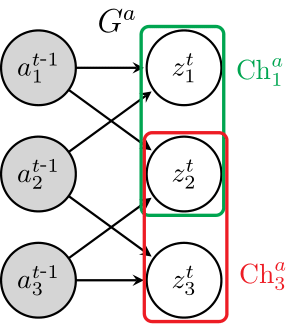
Sébastien Lachapelle, Pau Rodríguez López, Yash Sharma, Katie Everett, Rémi Le Priol Alexandre Lacoste Simon Lacoste-Julien CLeaR, 2022 paper / code Disentanglement, allowing for dependence between sequences of transitions, by identifying both the factors of variation and the sparse causal graphical model that relates them. |
|
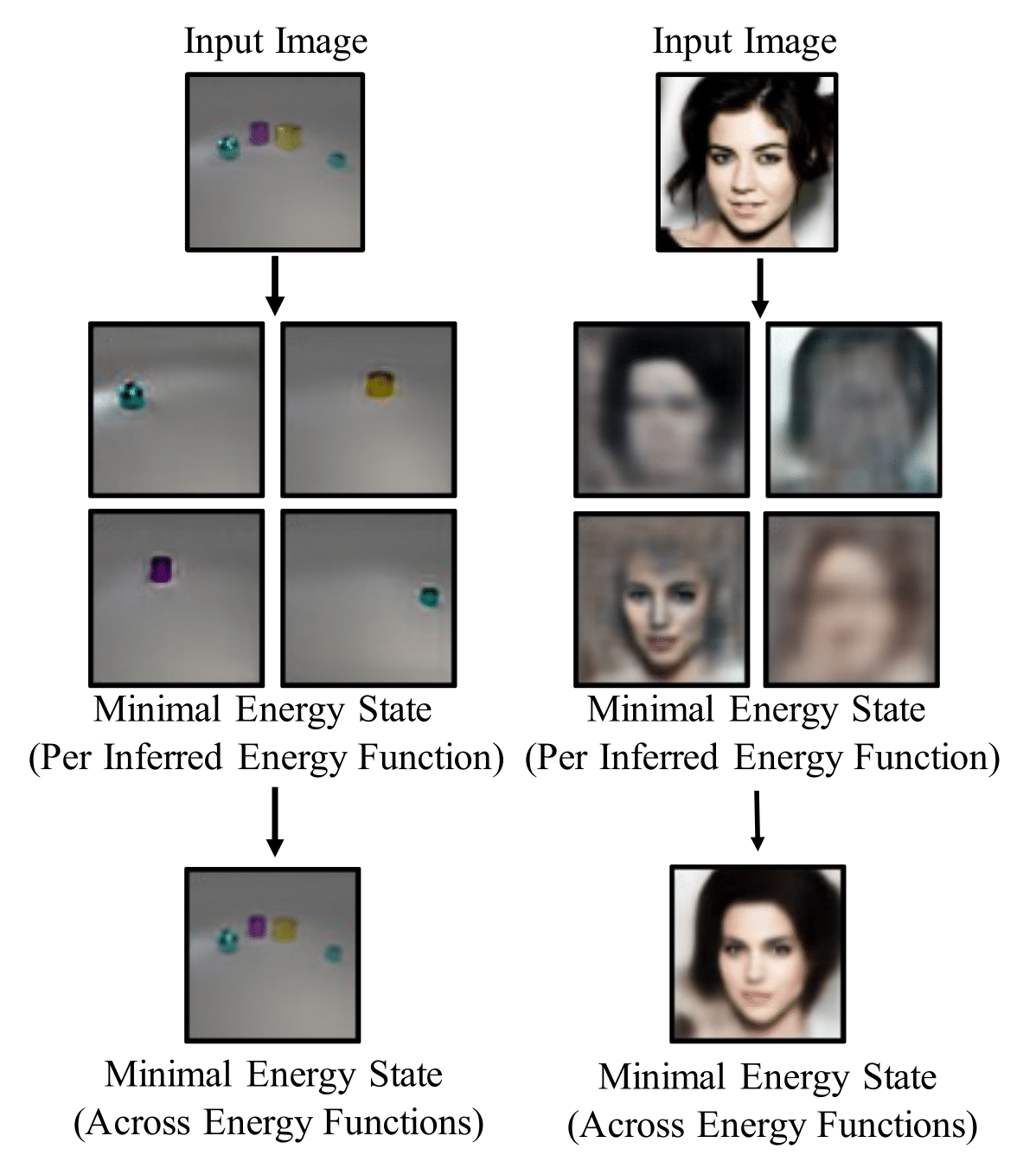
Yilun Du, Shuang Li, Yash Sharma, Josh Tenenbaum, Igor Mordatch NeurIPS, 2021 paper / website / code Enabled flexible compositions of discovered concepts, across modalities and datasets, by formulating sample generation as an optimization process on underlying energy functions. |

|
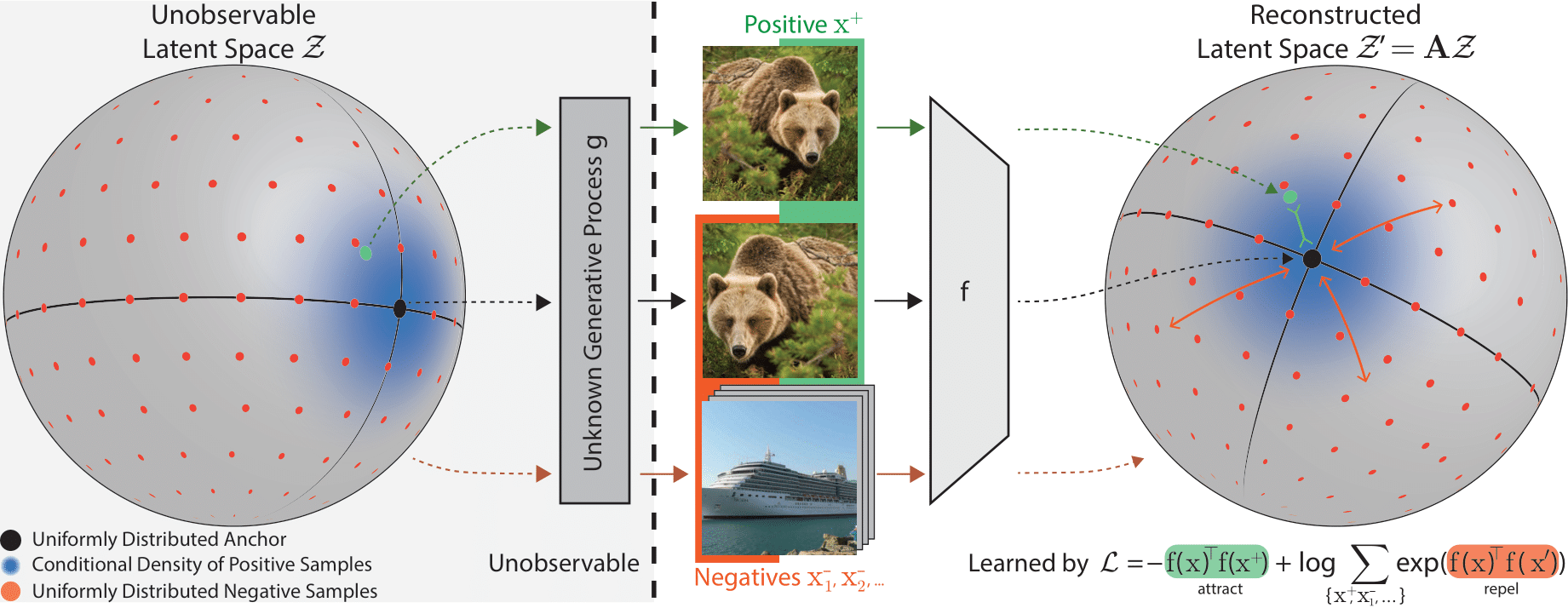
Julius von Kügelgen*, Yash Sharma*, Luigi Gresele*, Wieland Brendel, Bernhard Schölkopf, Michel Besserve, Francesco Locatello (*equal contribution) NeurIPS, 2021 ICML SSL Workshop, 2021 paper / code / talk We show that contrastive learning isolates the features data augmentations leave invariant, providing a proof of identifiability and empirical results on a novel visually complex benchmark with causal dependencies. |
|
Roland S. Zimmermann*, Yash Sharma*, Steffen Schneider*, Matthias Bethge, Wieland Brendel (*equal contribution) ICML, 2021 NeurIPS SSL Workshop, 2020 paper / website / code We show that contrastive learning can uncover the underlying factors of variation, with proofs and empirical success on a novel visually complex dataset. |
|
Marissa A. Weis, Kashyap Chitta, Yash Sharma, Wieland Brendel, Matthias Bethge, Andreas Geiger, Alexander Ecker JMLR, 2021 paper / code / talk Provide a video benchmark as well as an extension of a static method for unsupervised learning of object-centric representations for analysis. |

|
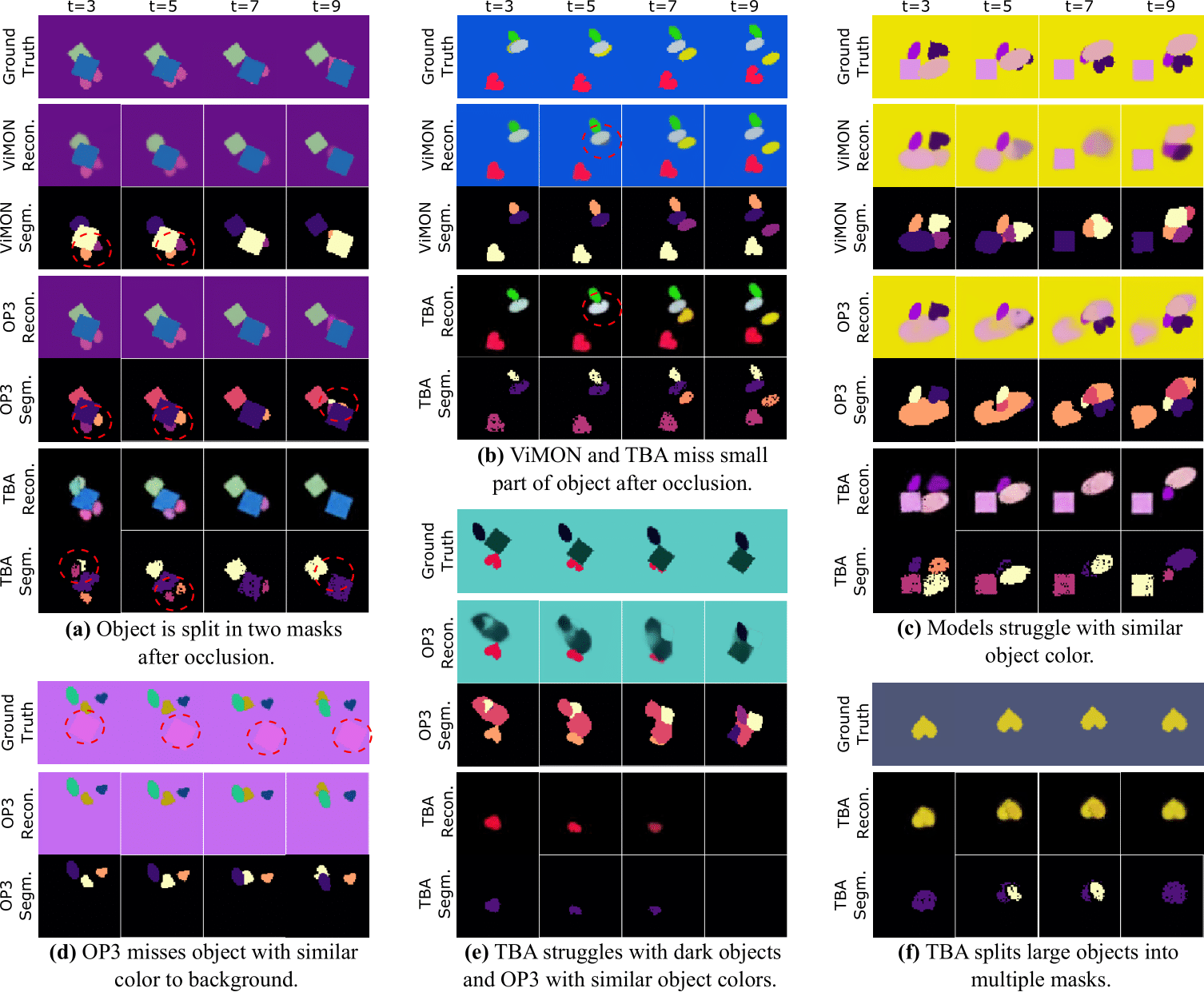
David Klindt*, Lukas Schott*, Yash Sharma*, Ivan Ustyuzhaninov, Wieland Brendel, Matthias Bethge, Dylan Paiton (*equal contribution) ICLR, 2021 (Oral; 53/2997 submissions) paper / code / oral / talk We show that accounting for the temporally sparse nature of natural transitions leads to a proof of identifiability and reliable learning of disentangled representations on several established benchmark datasets, as well as contributed datasets with natural dynamics. |
|
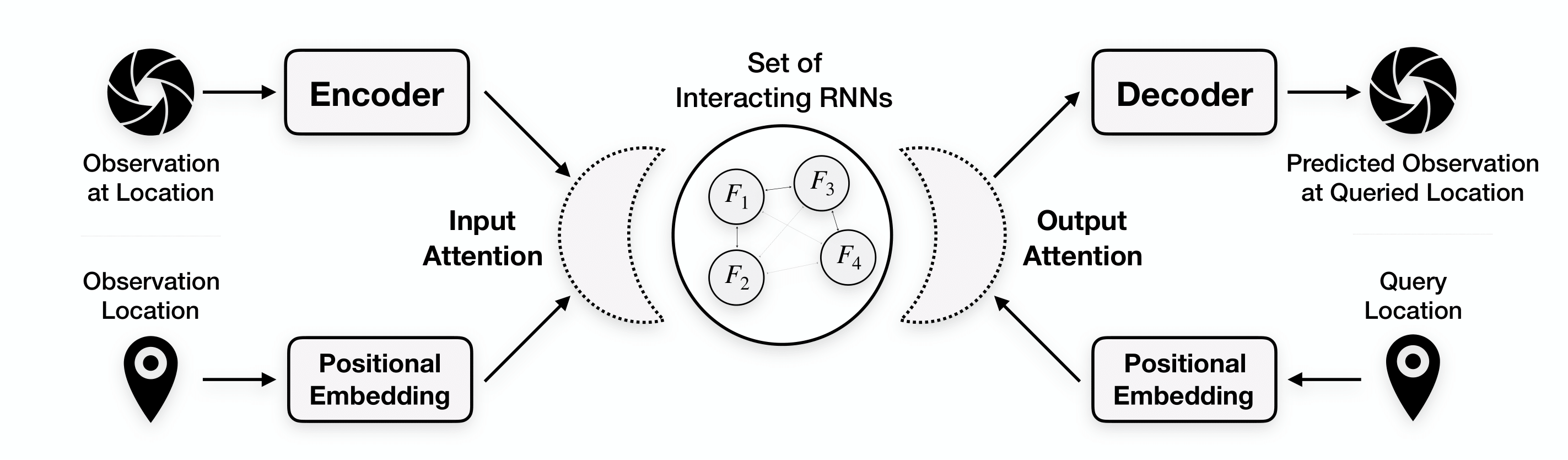
Nasim Rahaman, Anirudh Goyal, Muhammad Waleed Gondal, Manuel Wüthrich, Stefan Bauer, Yash Sharma, Yoshua Bengio, Bernhard Schölkopf ICLR, 2021 ICML BIG Workshop, 2020 paper / code Contribute a model class that is well suited for modeling the dynamics of systems that only offer local views into their state, along with corresponding spatial locations of those views. |
|
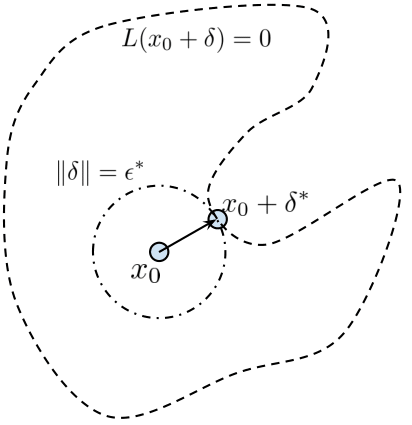
Gavin Weiguang Ding, Yash Sharma, Kry Yik Chau Lui, Ruitong Huang ICLR, 2020 ICLR SafeML Workshop, 2019 paper / code Directly maximizing input space margin removes the requirement of specifying a fixed distortion bound for improving adversarial robustness. |

|
Yash Sharma, Gavin Weiguang Ding, Marcus Brubaker IJCAI, 2019 paper / blog Defended ImageNet models based on adversarial training are roughly as vulnerable to low frequency perturbations as undefended models. |
|
Yingzhen Li, John Bradshaw, Yash Sharma ICML, 2019 ICML TADGM Workshop, 2018 paper / code Across factorization structures, provide evidence that generative classifiers are more robust to adversarial attacks than discriminative classifiers. |

|
Moustafa Alzantot, Yash Sharma, Supriyo Chakraborty, Huan Zhang, Cho-Jui Hsieh, Mani Srivastava GECCO, 2019 paper / code Evolutionary strategies can be used to synthesize adversarial examples in the black-box setting with orders of magnitude fewer queries than previous approaches. |

|
Yash Sharma, Tien-Dung Le, Moustafa Alzantot arXiv:1810.01268, 2018 paper / code / press Placed 1st, 1st, and 3rd in the targeted attack, non-targeted attack, and defense competitions, respectively, winning the competition overall. Prize: $38,000. |
|
Moustafa Alzantot*, Yash Sharma*, Ahmed Elgohary, Bo-Jhang Ho, Mani Srivastava, Kai-Wei Chang (*equal contribution) EMNLP, 2018 NeurIPS SecML Workshop (Encore Track), 2018 paper / code Generate adversarial examples that fool well-trained sentiment analysis and textual entailment models in the black-box setting while preserving semantics and syntactics of the original. |

|
Nicolas Papernot, Fartash Faghri, Nicholas Carlini, Ian Goodfellow, Reuben Feinman, Alexey Kurakin, Cihang Xie, Yash Sharma,... arXiv:1610.00768, 2018 paper / code Contributed to the CleverHans software library. |

|
Yash Sharma Master's Thesis, 2018 paper / slides Thesis Advisor: Sam Keene |
|
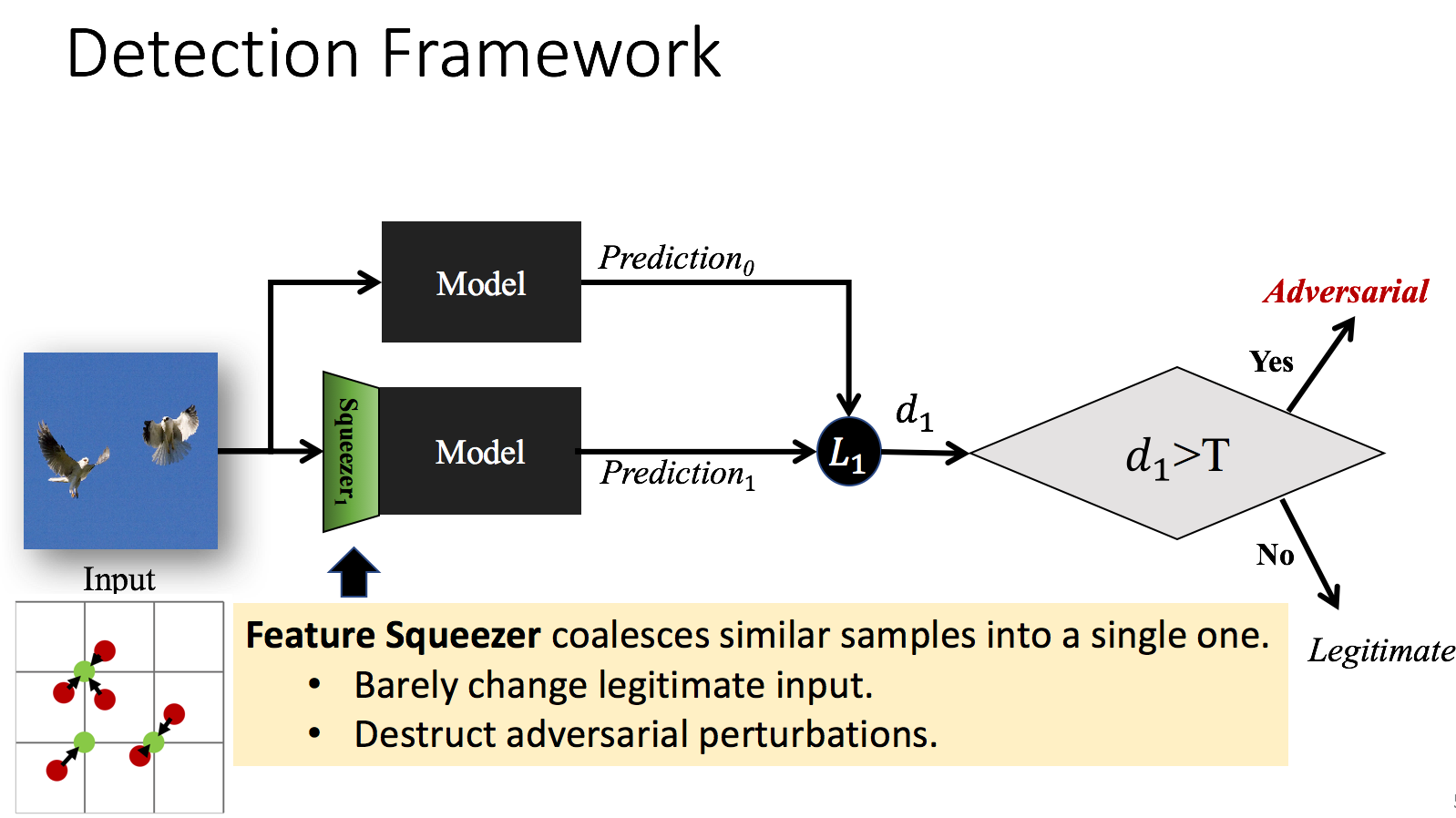
Yash Sharma, Pin-Yu Chen arXiv:1803.09868, 2018 paper Can bypass the feature squeezing detection framework with adversarial examples of minimal visual distortion by simply evaluating with stronger attack configurations. |

|
Yash Sharma, Pin-Yu Chen ICLR Workshop Track, 2018 paper Models adversarially trained on the L_inf metric are vulnerable to L1-based adversarial examples of minimal visual distortion. |
|
Pin-Yu Chen*, Yash Sharma*, Huan Zhang, Jinfeng Yi, Cho-Jui Hsieh (*equal contribution) AAAI, 2018 (Oral) paper / code Encouraging sparsity in the perturbation with L1 minimization leads to improved attack transferability and complements adversarial training. |
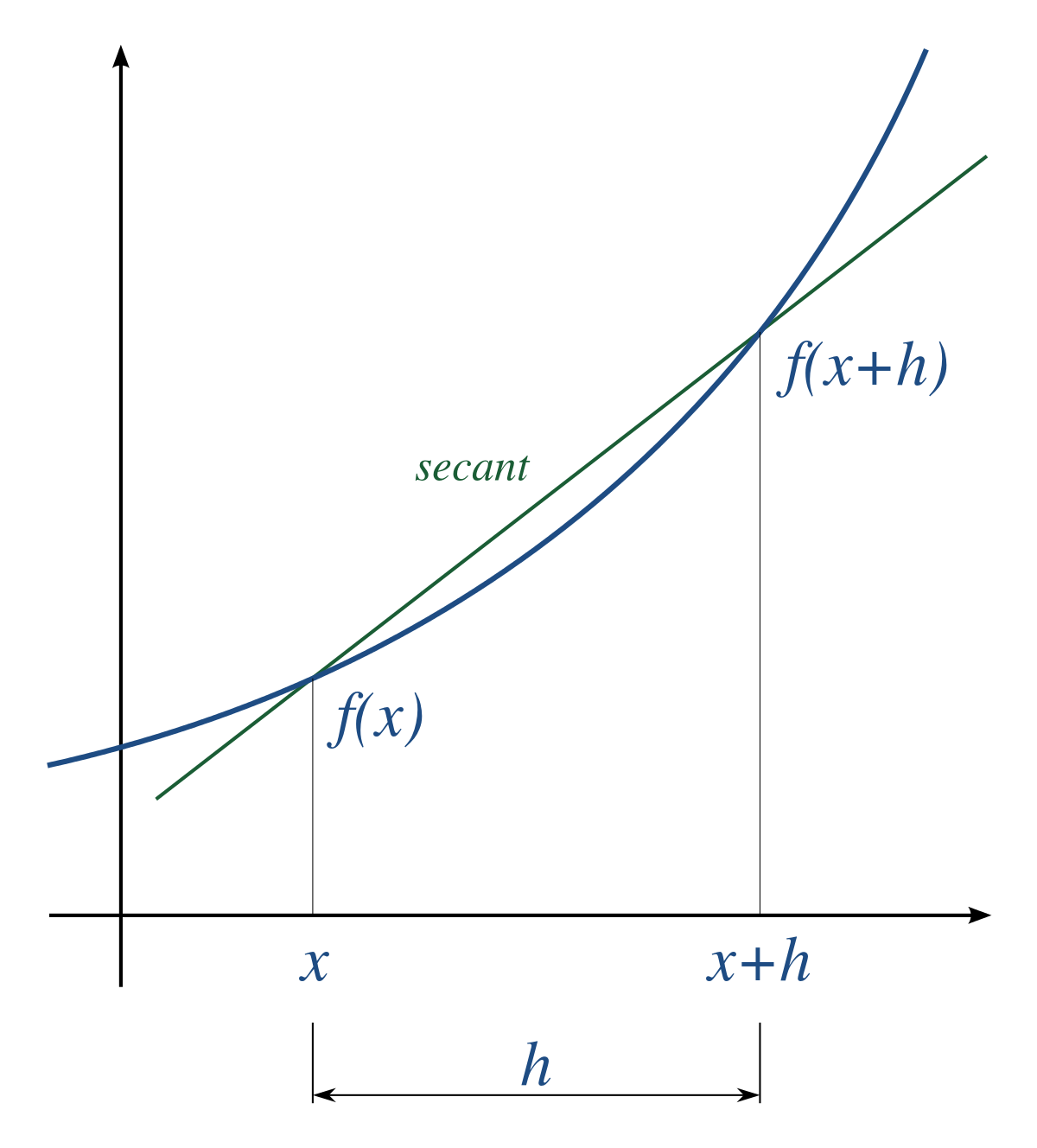
|
Pin-Yu Chen*, Huan Zhang*, Yash Sharma, Jinfeng Yi, Cho-Jui Hsieh (*equal contribution) ACM CCS AISec, 2017 (Best Paper Award Finalist) paper / code Directly estimate the gradients of the target model for generating adversarial examples in the black-box setting, sparing the need for training substitute models and avoiding the loss in attack transferability. |
|
|

|
Yuki Kubo, Anastasia Karpovich, Tien-Dung Le, Hieu Phung, Yash Sharma Solving Unseen Reasoning Tasks, 2020 solution Built set of functions based on implementing solutions for the provided tasks, searched for the correct composition for a given task at runtime. Served in mainly an advisory role. |

|
Yash Sharma, Moustafa Alzantot, Supriyo Chakraborty, Tianwei Xing, Sikai Yin, Mani Srivastava NeurIPS Competition Track, 2017 code Teamed with UCNesl to finish with one gold and two silver medals in the competition track. |
|
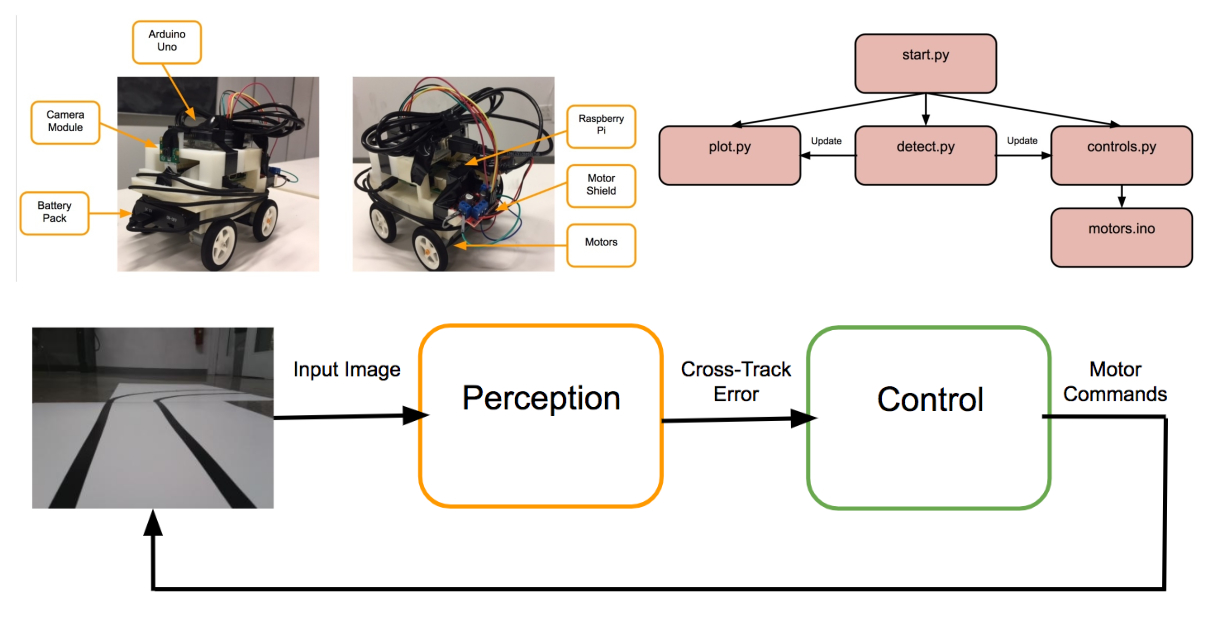
Yash Sharma, Vishnu Kaimal Senior Project, 2017-2018 IEEE Student Paper, 2018 full report / writeup / poster / demo Built an autonomous vehicle which can navigate through maps consisting of various road topologies. |
|
Yash Sharma, Eli Friedman Deep Learning Final Project, 2017 report Stabilized the training of competitive agents under human-level action delay through adding recurrence to the DQN architecture. |
|
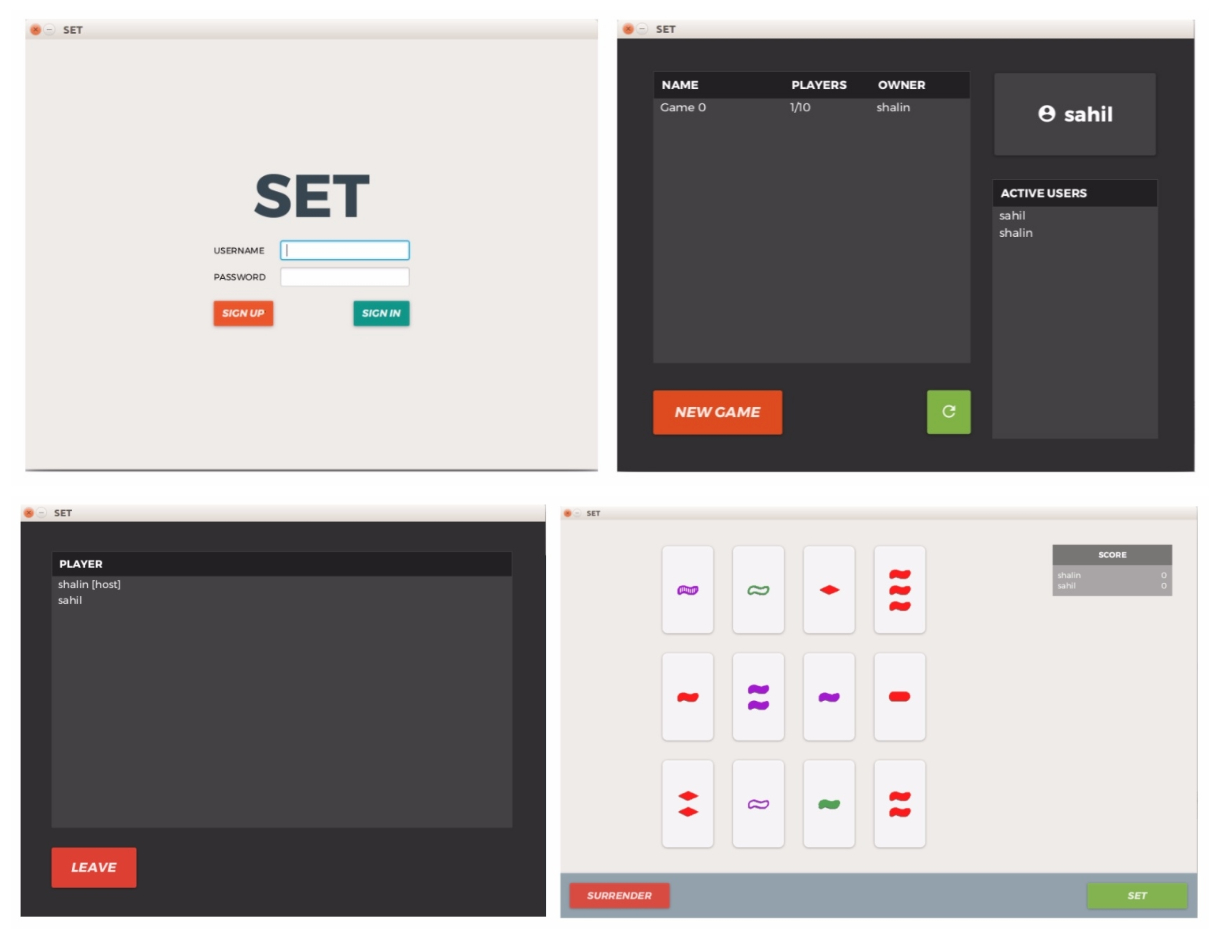
Yash Sharma, Sahil Patel, Shalin Patel, Kevin Sheng Software Engineering Final Project, 2017 code / slides Developed a client-server application which allows users to play the game of SET against each other over the network. |
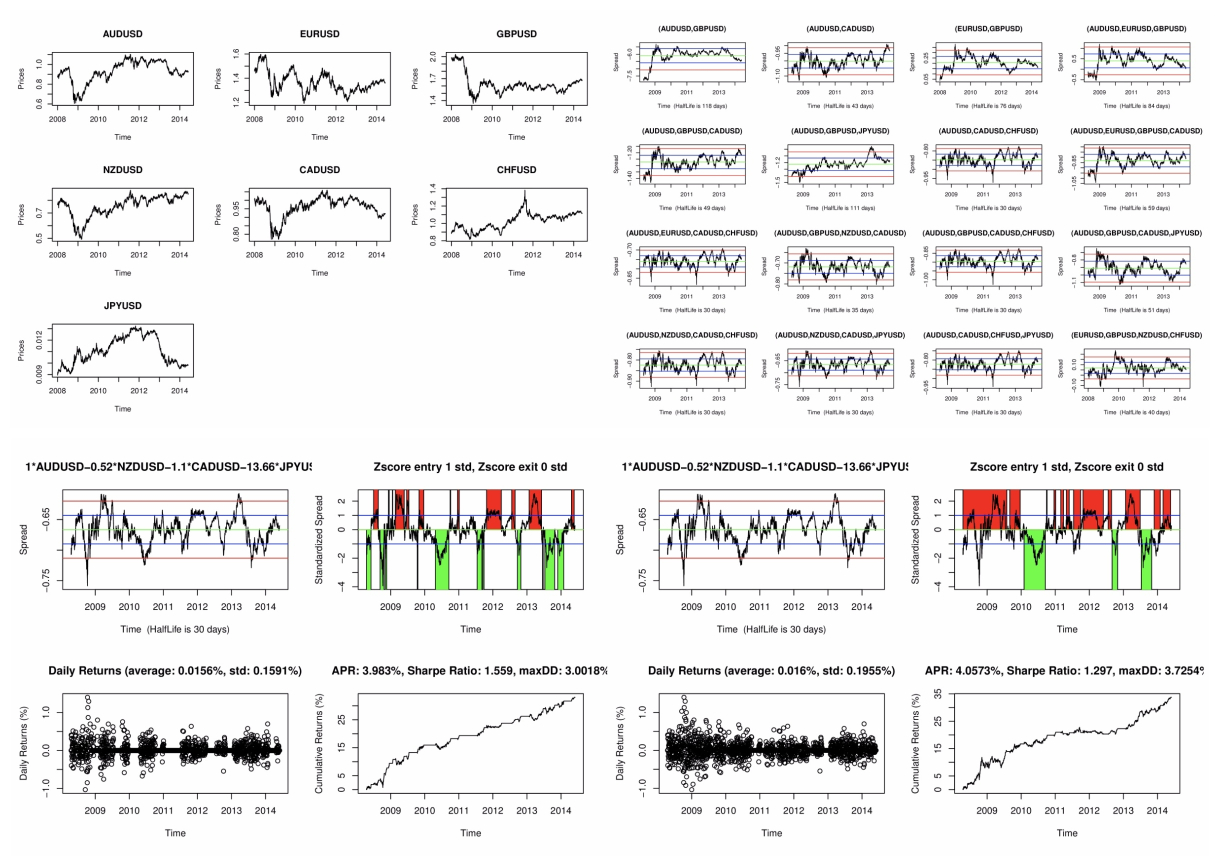
|
Yash Sharma Business Economics Final Project, 2017 paper / code Implemented a multiple pairs trading strategy on major currency pairs and improved the APR over the evaluation period by factoring in forecasts of a series of pertinent macroeconomic variables by optimizing the weights of the trading signals. |
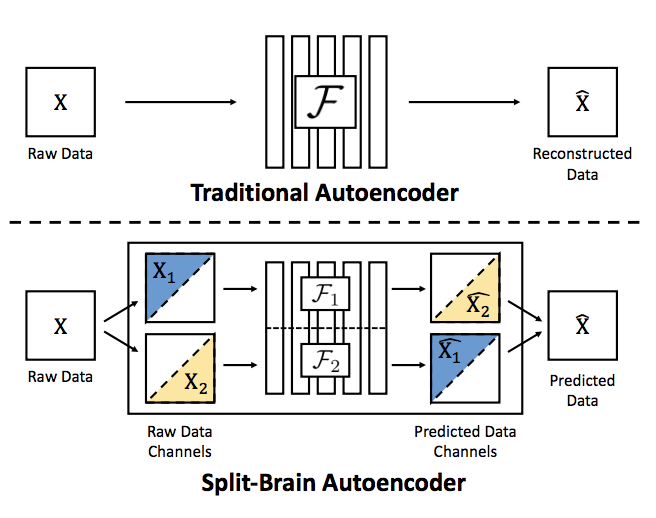
|
Yash Sharma, Sahil Patel Deep Learning Midterm Project, 2017 code Implemented the Split-Brain Autoencoder in TensorFlow and showed that the extracted features can help supervised learning when labeling is costly. |

|
Yash Sharma, Brenda So, Shalin Patel CodeSuisse Hackathon (Winner), 2016 code Built an android application which allows users to record notes about their meetings, write messages that will be displayed on a Twitter-like feed, and determine viability of initiatives regarding specific tickers through sentiment analysis run on written logs. |
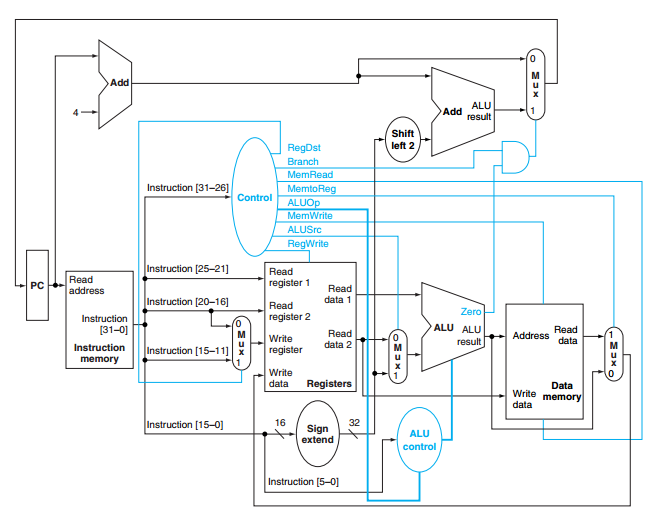
|
Yash Sharma, Shalin Patel, Matt Cavallaro Computer Architecture Final Project, 2016 code Built an 8-bit single-cycle processor with a 4-byte cache for data memory capable of executing nested procedures, leaf procedures, signed addition, loops, and recursion. |
|
Yash Sharma, Brenda So, Sahil Patel, Gordon Su IBM Sparkathon, 2016 code / dataset Traced the sources of pollution in the continental United States through compiling data from the EPA, NOAA, and Google Maps API, estimating the parameters of a gaussian dispersion model, and predicting pollutant concentration in the future with linear regression. |
|
Template: here |